

Workflows and agents
This guide reviews common patterns for agentic systems. In describing these systems, it can be useful to make a distinction between “workflows” and “agents”. One way to think about this difference is nicely explained in Anthropic’s 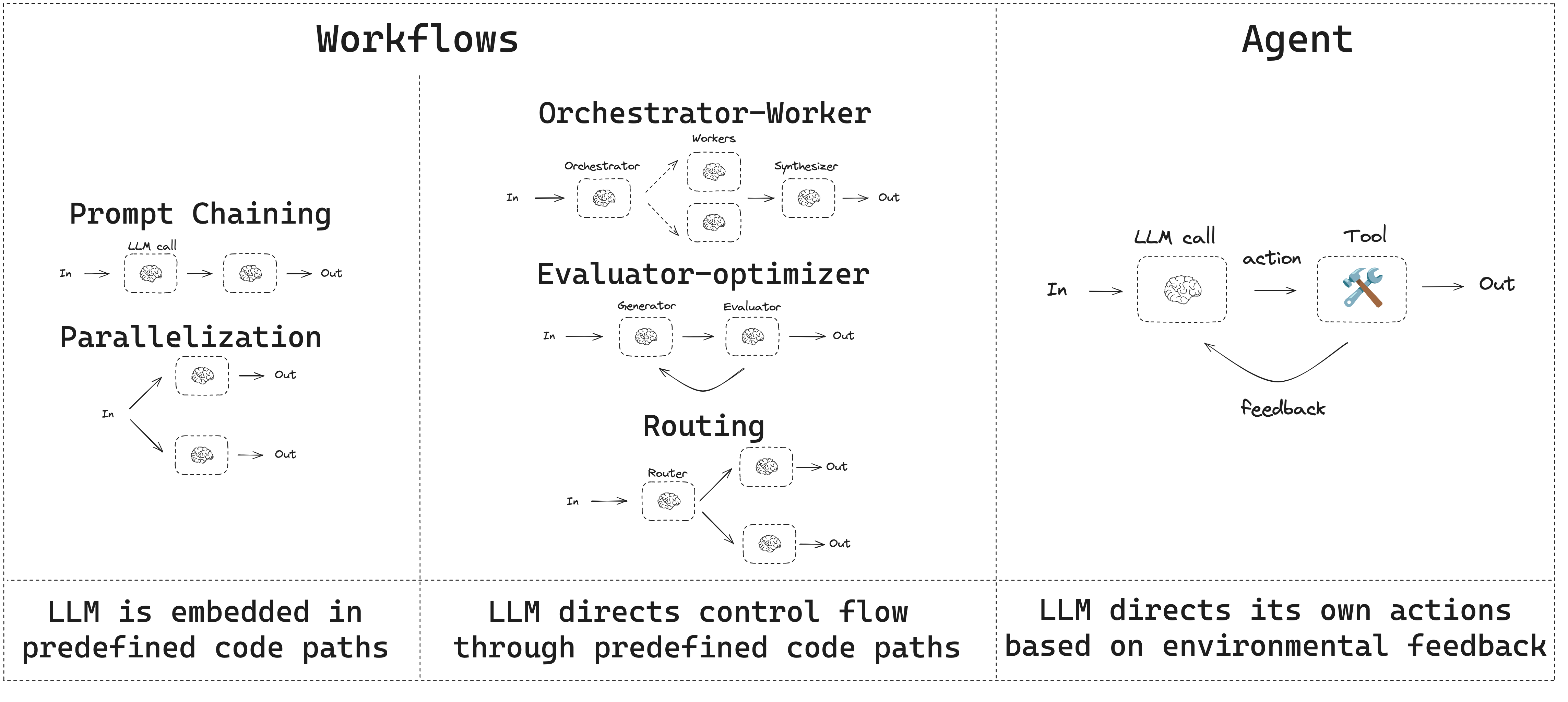 When building agents and workflows, LangGraph offers a number of benefits including persistence, streaming, and support for debugging as well as deployment.
Initialize an LLM
When building agents and workflows, LangGraph offers a number of benefits including persistence, streaming, and support for debugging as well as deployment.
Initialize an LLM
 Creating Workers in LangGraphBecause orchestrator-worker workflows are common, LangGraph has the
Creating Workers in LangGraphBecause orchestrator-worker workflows are common, LangGraph has the
Building Effective Agents blog post:
Workflows are systems where LLMs and tools are orchestrated through predefined code paths. Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.Here is a simple way to visualize these differences:
When building agents and workflows, LangGraph offers a number of benefits including persistence, streaming, and support for debugging as well as deployment.
Set up
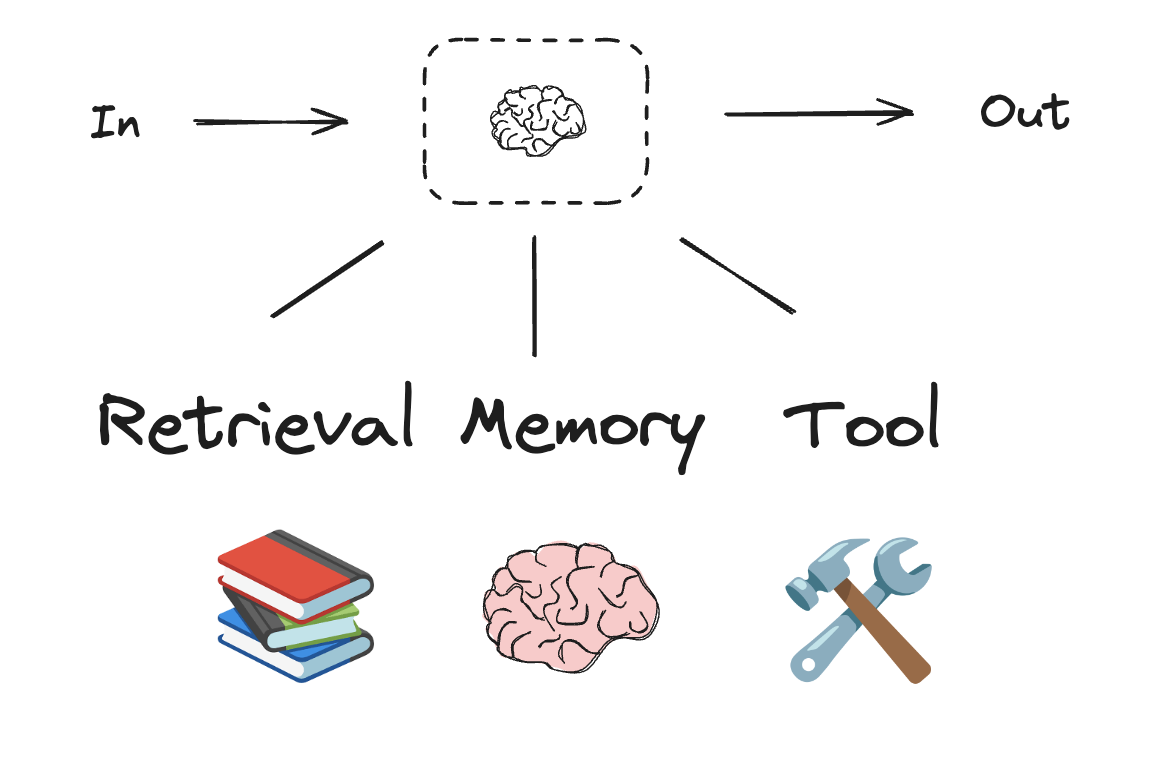
You can use any chat model that supports structured outputs and tool calling. Below, we show the process of installing the packages, setting API keys, and testing structured outputs / tool calling for Anthropic. Install dependenciesBuilding Blocks: The Augmented LLM
LLM have augmentations that support building workflows and agents. These include structured outputs and tool calling, as shown in this image from the Anthropic blog onBuilding Effective Agents:
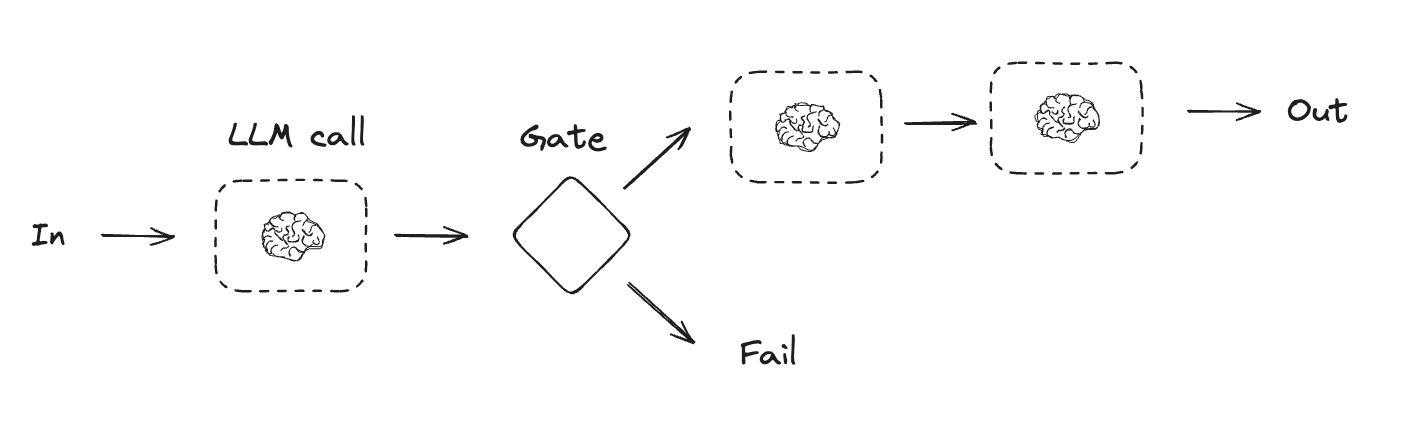
Prompt chaining
In prompt chaining, each LLM call processes the output of the previous one. As noted in the Anthropic blog onBuilding Effective Agents:
Prompt chaining decomposes a task into a sequence of steps, where each LLM call processes the output of the previous one. You can add programmatic checks (see “gate” in the diagram below) on any intermediate steps to ensure that the process is still on track.
When to use this workflow: This workflow is ideal for situations where the task can be easily and cleanly decomposed into fixed subtasks. The main goal is to trade off latency for higher accuracy, by making each LLM call an easier task.
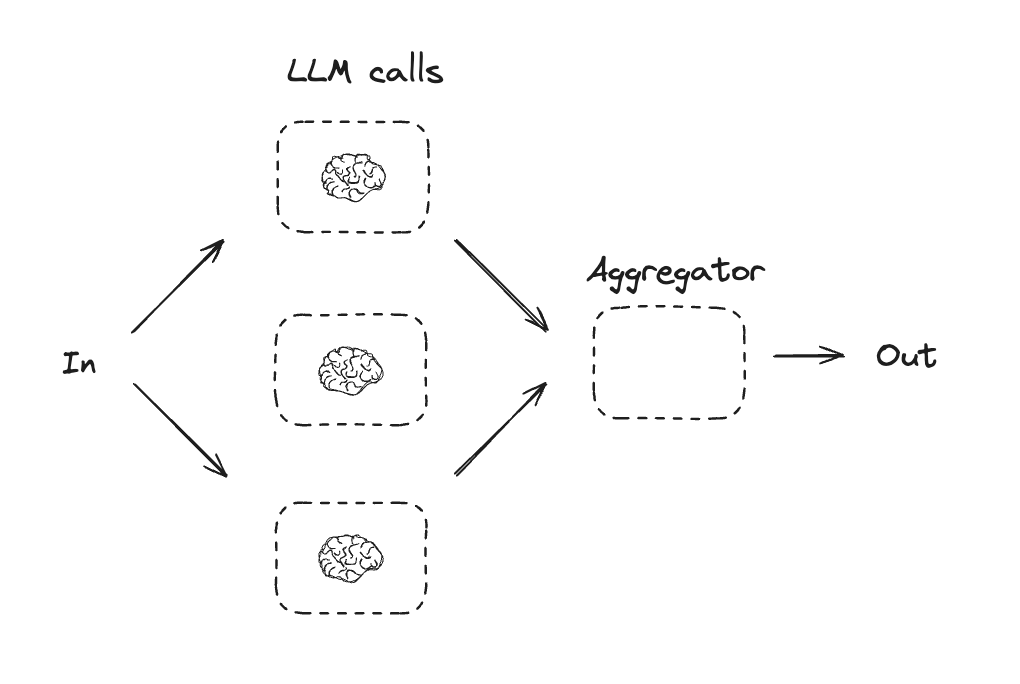
Parallelization
With parallelization, LLMs work simultaneously on a task:LLMs can sometimes work simultaneously on a task and have their outputs aggregated programmatically. This workflow, parallelization, manifests in two key variations: Sectioning: Breaking a task into independent subtasks run in parallel. Voting: Running the same task multiple times to get diverse outputs.
When to use this workflow: Parallelization is effective when the divided subtasks can be parallelized for speed, or when multiple perspectives or attempts are needed for higher confidence results. For complex tasks with multiple considerations, LLMs generally perform better when each consideration is handled by a separate LLM call, allowing focused attention on each specific aspect.
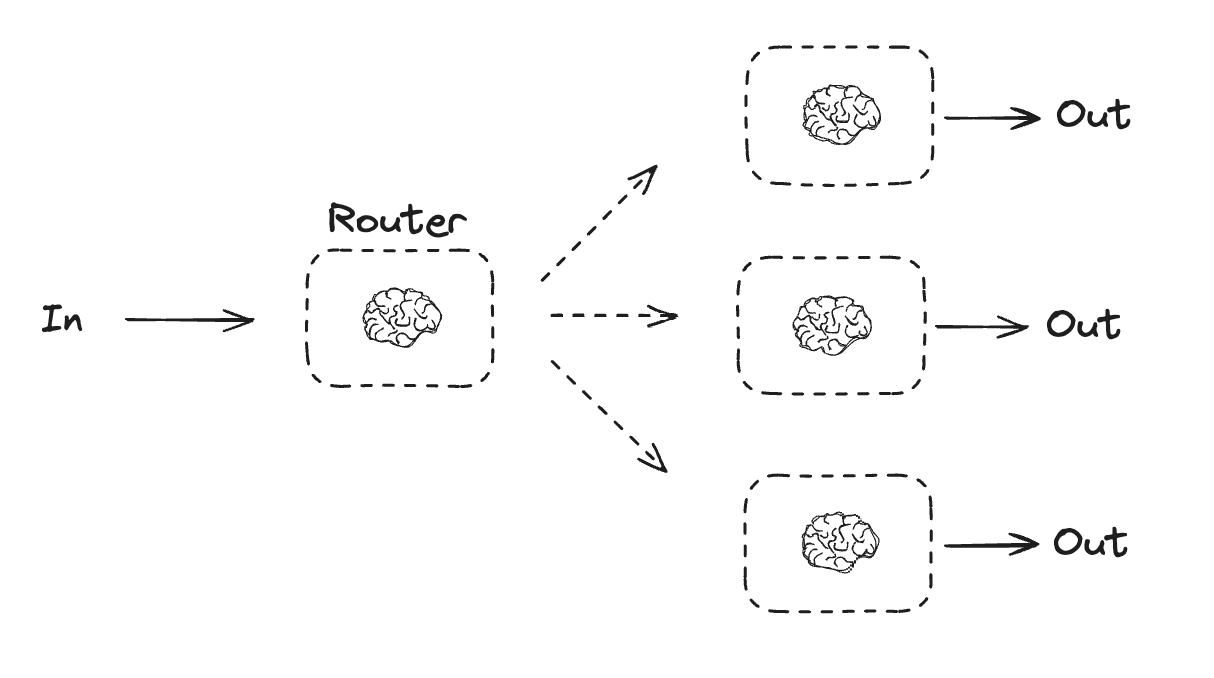
Routing
Routing classifies an input and directs it to a followup task. As noted in the Anthropic blog onBuilding Effective Agents:
Routing classifies an input and directs it to a specialized followup task. This workflow allows for separation of concerns, and building more specialized prompts. Without this workflow, optimizing for one kind of input can hurt performance on other inputs.
When to use this workflow: Routing works well for complex tasks where there are distinct categories that are better handled separately, and where classification can be handled accurately, either by an LLM or a more traditional classification model/algorithm.
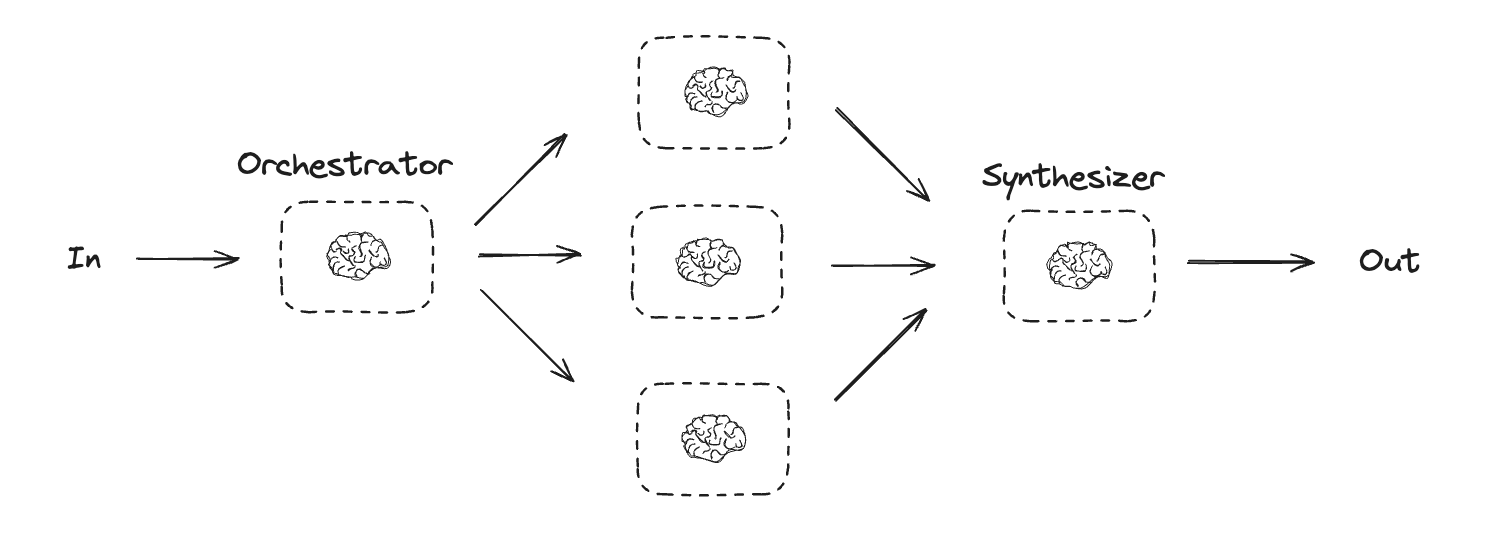
Orchestrator-Worker
With orchestrator-worker, an orchestrator breaks down a task and delegates each sub-task to workers. As noted in the Anthropic blog onBuilding Effective Agents:
In the orchestrator-workers workflow, a central LLM dynamically breaks down tasks, delegates them to worker LLMs, and synthesizes their results.
When to use this workflow: This workflow is well-suited for complex tasks where you can’t predict the subtasks needed (in coding, for example, the number of files that need to be changed and the nature of the change in each file likely depend on the task). Whereas it’s topographically similar, the key difference from parallelization is its flexibility—subtasks aren’t pre-defined, but determined by the orchestrator based on the specific input.
Send API to support this. It lets you dynamically create worker nodes and send each one a specific input. Each worker has its own state, and all worker outputs are written to a shared state key that is accessible to the orchestrator graph. This gives the orchestrator access to all worker output and allows it to synthesize them into a final output. As you can see below, we iterate over a list of sections and Send each to a worker node. See further documentation here and here.Evaluator-optimizer
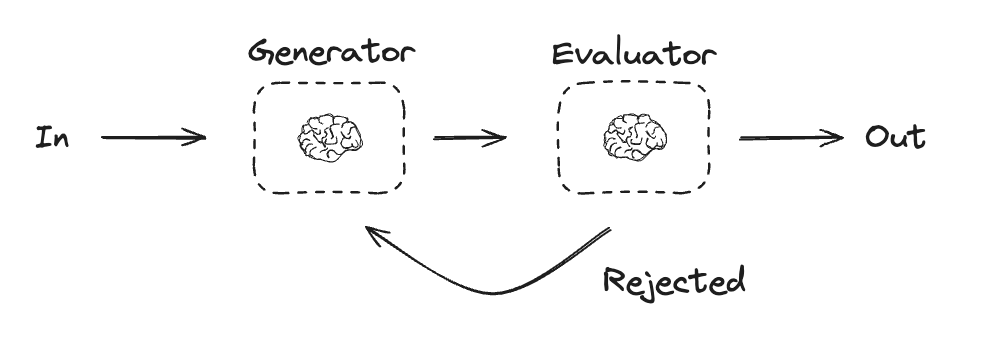
In the evaluator-optimizer workflow, one LLM call generates a response while another provides evaluation and feedback in a loop:When to use this workflow: This workflow is particularly effective when we have clear evaluation criteria, and when iterative refinement provides measurable value. The two signs of good fit are, first, that LLM responses can be demonstrably improved when a human articulates their feedback; and second, that the LLM can provide such feedback. This is analogous to the iterative writing process a human writer might go through when producing a polished document.
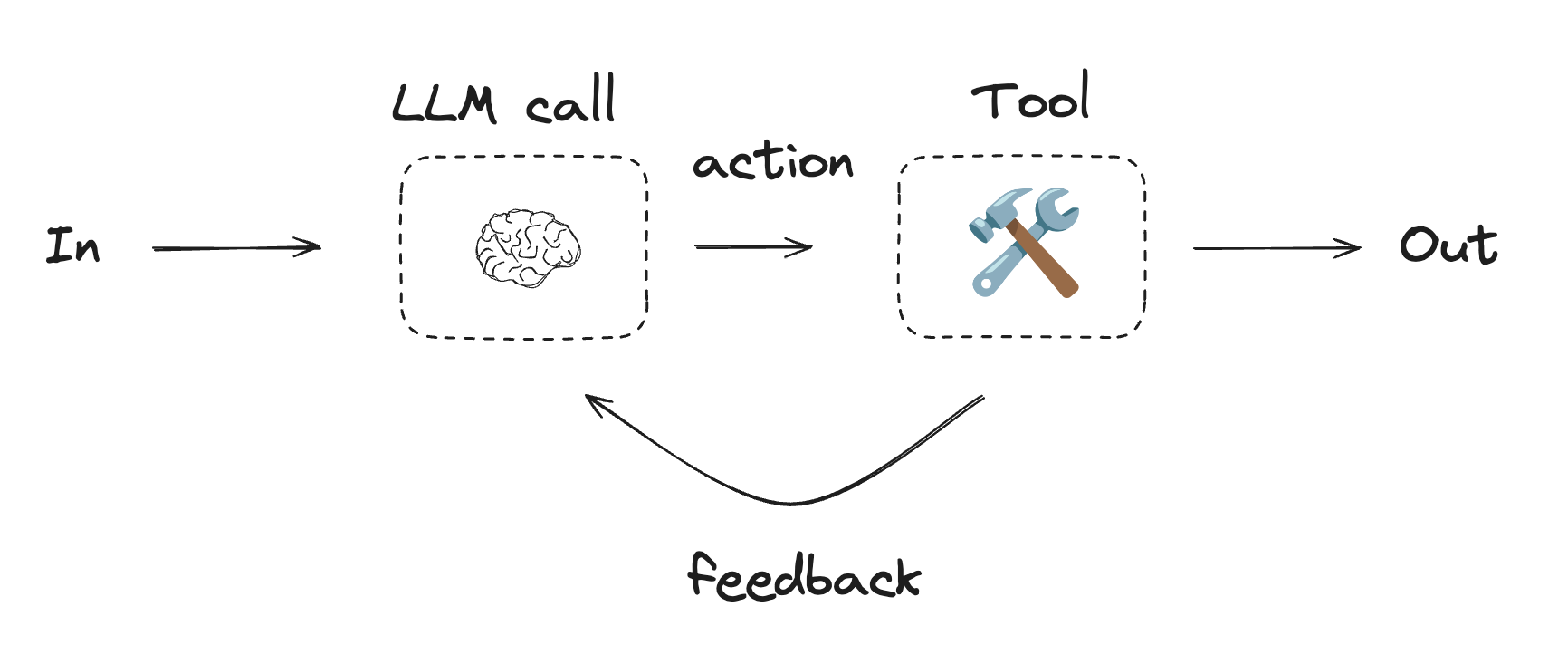
Agent
Agents are typically implemented as an LLM performing actions (via tool-calling) based on environmental feedback in a loop. As noted in the Anthropic blog onBuilding Effective Agents:
Agents can handle sophisticated tasks, but their implementation is often straightforward. They are typically just LLMs using tools based on environmental feedback in a loop. It is therefore crucial to design toolsets and their documentation clearly and thoughtfully.
When to use agents: Agents can be used for open-ended problems where it’s difficult or impossible to predict the required number of steps, and where you can’t hardcode a fixed path. The LLM will potentially operate for many turns, and you must have some level of trust in its decision-making. Agents’ autonomy makes them ideal for scaling tasks in trusted environments.
Pre-built
LangGraph also provides a pre-built method for creating an agent as defined above (using thecreateReactAgent function):